Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
ICCV 2021
-
Abhishek Aich
UC Riverside -
Meng Zheng
UII, America -
Srikrishna Karanam
UII, America -
Terrence Chen
UII, America -
Amit K. Roy-Chowdhury
UC Riverside -
Ziyan Wu
UII, America
Abstract
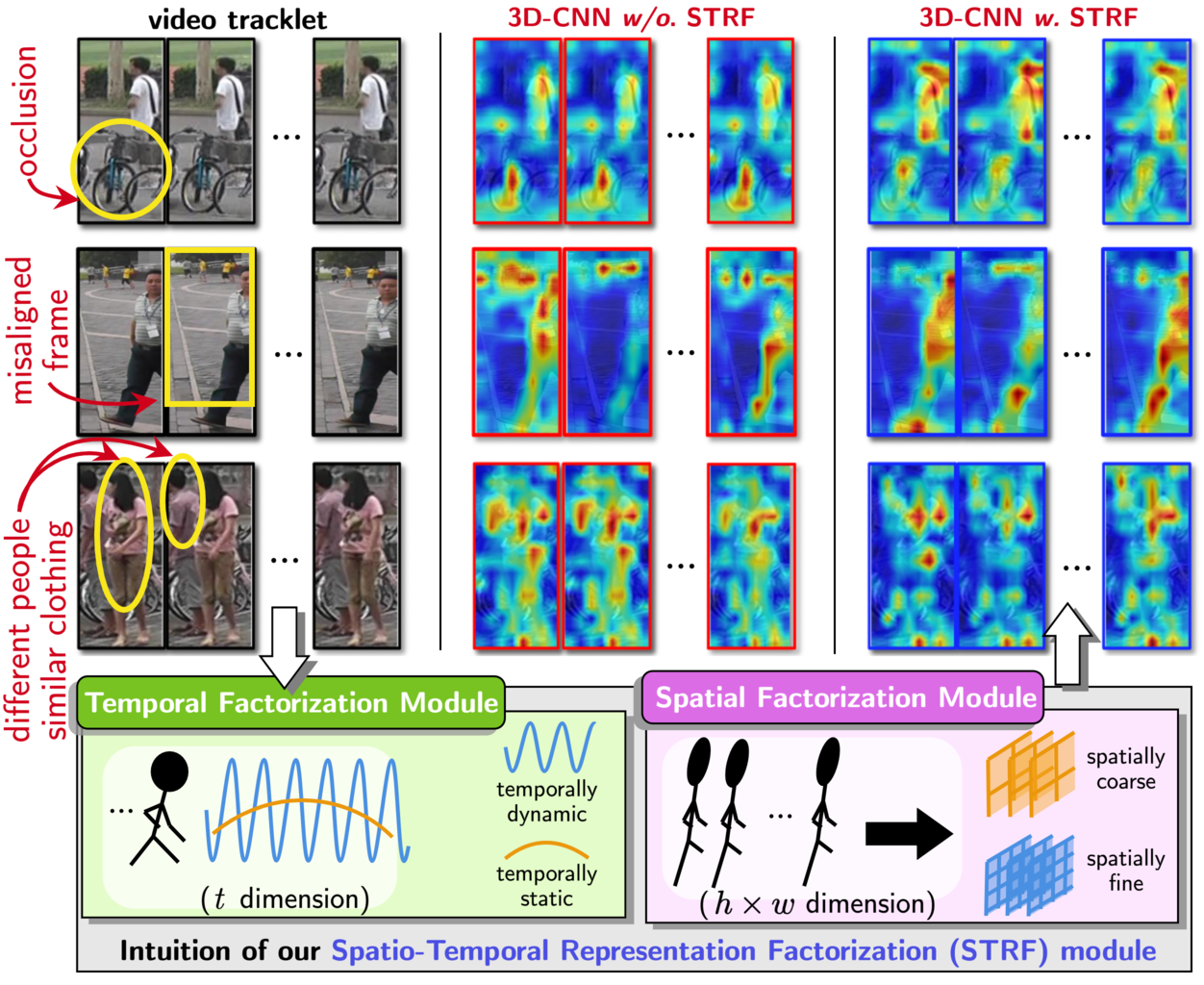
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.
BibTeX
@InProceedings{aich2021spatio,
title={Spatio-temporal representation factorization for video-based person re-identification},
author={Aich, Abhishek and Zheng, Meng and Karanam, Srikrishna and Chen, Terrence and Roy-Chowdhury, Amit K and Wu, Ziyan},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages = {152--162},
year={2021}
}
Acknowledgements
This work was partially supported by ONR grants N00014-19-1-2264 and N0001.